This step is an easy one, but essential. Stata has a log function that records all of the commands. This gives a running record of every command you entered, whether it was typed or done in the menus. Clearly, you may want to look back at descriptive statistics, regression diagnostics or other results to check on your work.
You can also add comments in your log, which is helpful when you read your log two months later and wonder why exactly
arima D.crime, ar(1) ma(1), vce(robust)
is different from
arima crime, arima(1,1,0) sarima(0,1,1),
and which one is better.
So you can add comments to explain this to your future self by typing the * before some explanation, like this:
arima D.crime, ar(1) ma(1), vce(robust)
* This command models a differenced time-series with first-order autoregression with robust standard error estimation
arima crime, arima(1,1,0) sarima(0,1,1)
* This command models a seasonally differenced series with a seasonal moving average and first-order autoregression.
The best way to read old logs is in the Stata viewer, because it highlights and formats everything quite naturally.
You can log in the command window by just typing:
log using FILENAME
However, because you need the full extension, it's usually easier to click the log button:

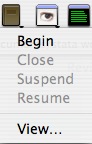
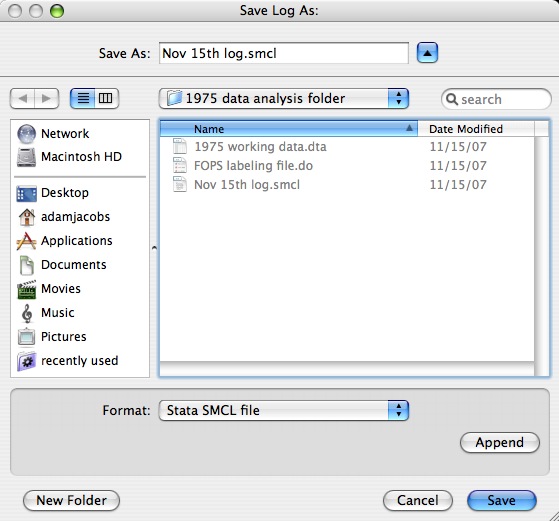
Notice that you can append logs onto already existing files. This is handy if you want a complete running record of everything you did with a specific dataset.
I'd like to figure out how to make date-specific log files, but I don't have it working quite yet.
Incorporating the current date and time is explained more fully on this page from the Stata site.
Those are the basic five steps. Next we'll deal with 5 advanced Mac/Stata tips.