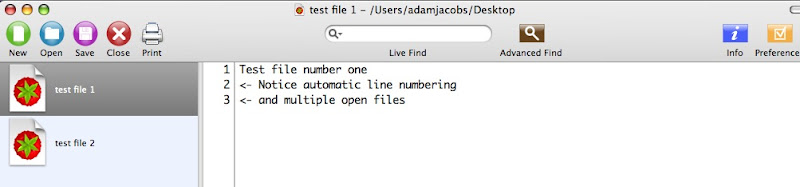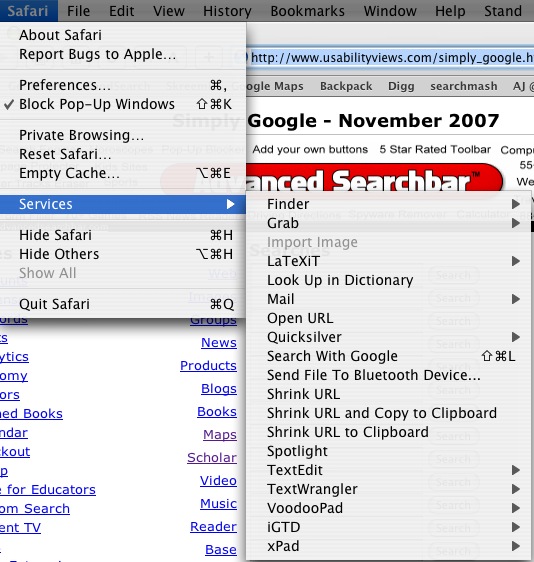
Most people never use this menu, even though it can be tremendously time-saving. That's probably because the few useful services are lost within all the other ones, so the menu is a bit of a time waster.
First of all, let's reduce the number of services available. There are a huge number that most people will never use: Chinese Text Convertor is an obvious one for me, as well as Disk Utility and Speech Items. I think I'll remove a few more after looking at this screenshot, as I can't remember ever using "Send to Bluetooth Device" (I don't have any), and "TextEdit" and "Xpad" have been replaced by TextWrangler.
To remove services, download the freeware ServiceScrubber. You can just de-select the irrelevant ones:

And here it is, even more minimal than before:
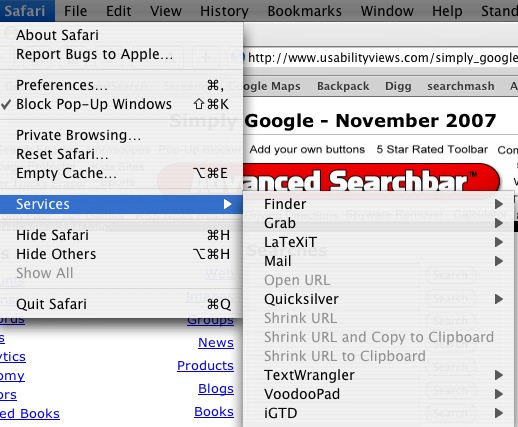
Now, time to use Services. Suppose we're browsing trying to find the right Stata code on the company website. I'd like to find some information on seasonal ARIMA models, which tend to model crime rates pretty well. Looking around on Statalist, the help forum, I see a snippet of text that looks like what I'm interested in:
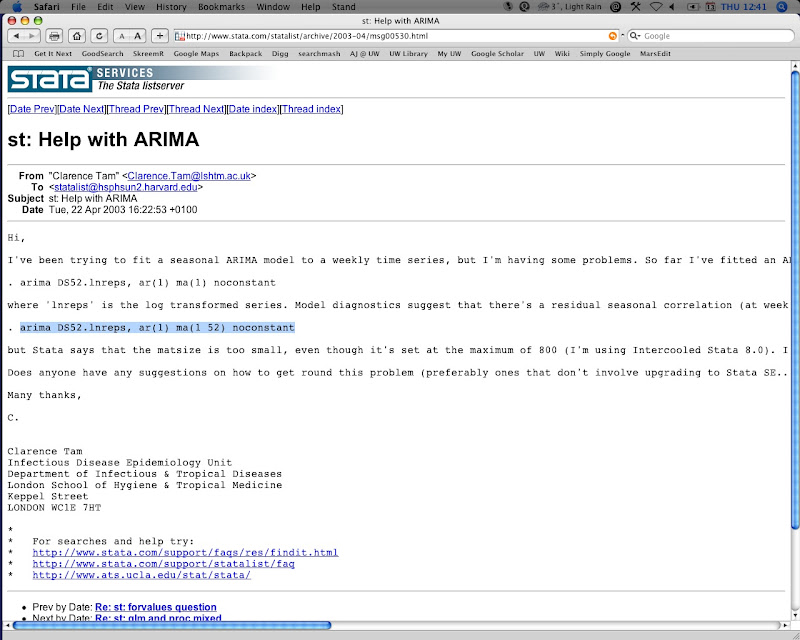
I select the text and then look in Services:

And once clicked, you have a new Textwrangler file with the desired text copied right in.
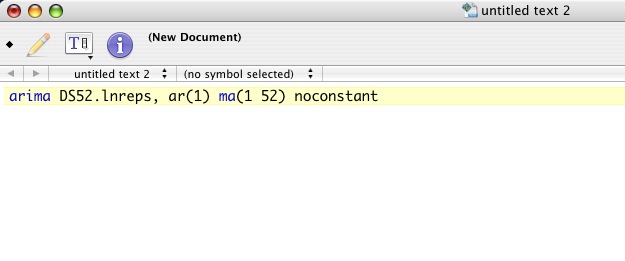
This comes in very handy when you're browsing and find a link you'd like to add to a text file, or a quote you won't remember but want to record. Start using Services and it will help keep the massive amounts of information organized. You may want to just setup a file to dump all of these things into. I use Voodoopad for random clippings that might be helpful or interesting but can't be read right now.
Technorati Tags:
Mac OS X, Stata, statistical software, text editors, TextWrangler